
1. 서론
아침에 회사 DB가 두 번이나 터졌다. 종종 발생하던 문제임을 감안했을 때, 데이터를 인위적으로 서비스 도중에 밀어넣을 때 발생했다는 생각이 들었다.
서버에서는 비즈니스 로직 수행을 위해 DB에 Query, Mutation 요청을 한다. 이 경우 DB에서는 비즈니스 로직에서 필요로 하는 테이블로부터 요청한 데이터를 찾기 위한 동작을 진행한다. 내 상황의 경우 서비스 되고 있던 서버이기 때문에 비즈니스 로직 상 다량의 조회가 발생하는 테이블에 값을 밀어넣었을 때 문제가 생겼다고 생각했다.
여기서 한가지 의문이 생겼다. 시스템이 서비스 중인 상황을 감안하여 사용이 덜 될 것 같은 데이터를 입력했는데, 그럼에도 불구하고 DB부하가 걸리는 이유가 궁금했다. 이에 찾던 중 얻은 실마리가 Explain 이었다.
2. 그래서, Explain이 뭔데?
Explain은 입력한 쿼리가 DB 내부적으로 어떻게 실행될 지 알려주는 문법이다. 그렇기 때문에, 일반적으로 사용할 쿼리 앞에 explain을 붙이면 된다.
EXPLAIN SELECT ... # 쿼리 입력.
예시를 보자. 사용자 테이블이 있다(하단 참조). User 테이블에는 user_name 속성을 갖고 있다.
| User |
| user_name |
우리는 이 테이블에서 이름에 '김'이 포함되는 사람을 찾는다고 가정하자. EXPLAIN을 사용한 SQL과 결과를 살펴보자.
EXPLAIN SELECT COUNT(*) FROM user WHERE user_name like '%김%';

이제부터, 각 컬럼의 역할을 살펴보자.
| 컬럼 | 설명 |
|---|---|
| id | 쿼리의 실행 순서를 나타냅니다. 값이 클수록 우선순위가 높으며, 복잡한 조인 쿼리에서는 여러 단계로 나눠 실행됩니다. 예: NULL은 결과를 병합하거나 하위 쿼리의 결과를 사용하는 경우. |
| select_type | 쿼리의 유형을 나타냅니다. 주요 값:
|
| table | 현재 분석 중인 테이블의 이름. |
| type | 테이블 접근 방식(조인 유형)을 나타냅니다. 효율 순서:
|
| possible_keys | MySQL이 사용할 수 있는 인덱스의 목록. NULL이면 사용 가능한 인덱스가 없음을 의미. |
| key | 실제로 사용된 인덱스. |
| key_len | MySQL이 선택한 인덱스의 키 길이를 나타냅니다. 인덱스가 사용된 경우 얼마나 많은 부분이 사용되었는지 확인 가능. |
| ref | 조인에서 비교된 열 또는 상수를 나타냅니다. 예: const, func, field_name. |
| rows | MySQL이 쿼리 실행 시 검사할 것으로 예상되는 행 수. 값이 클수록 쿼리가 더 많은 데이터를 처리하므로 최적화를 고려해야 합니다. |
| filtered | 조건을 만족하는 행의 비율(백분율). 최종 출력 행 수는 rows * filtered / 100로 계산됩니다. |
| Extra | 추가적인 실행 세부사항을 표시. 주요 값:
|
예시의 경우 전체 테이블을 스캔하고, 서브쿼리 및 유니온 등이 없고, where절을 사용한 쿼리가 실행될 것을 이야기한다.
3. 근데, 뭔가 이상하다?
그런데, 실제 이름에 김이 포함된 사람의 수는 아래 사진과 같다.
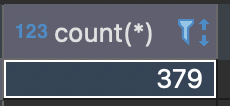
왜 김씨는 379 명인데, 379개 데이터가 아닌 1581개를 조회할까?
...
...
...
다음 기회에!
*위 글에는 틀리거나 주관적 의견이 포함되어 있을 수 있습니다. 비판이나 의견 제시를 해주시면 감사히 받겠습니다.*
'Computer Science > 데이터베이스' 카테고리의 다른 글
| [Mysql] Upsert란? - 1 (Insert, Update 동시에 하기) (3) | 2024.12.26 |
|---|---|
| [MariaDB] 데이터 타입 종류 정리해서 보자! (0) | 2023.07.28 |
| Transaction이란? - 1 (정의, 특징-ACID) (2) | 2023.05.02 |
| [SQL, MariaDB] 한 테이블의 특정 컬럼에 있는 값이 다른 컬럼에 없는 레코드 탐색. (0) | 2023.03.14 |